机器翻译发展变化趋势
机器翻译(MT)是借机器之力,自动地将一种自然语言文本(源语言)翻译成另一种自然语言文本(目标语言)。使用机器做翻译的思想最早由 Warren Weaver 于 1949 年提出,在很长一段时间里(20 世纪 50 年代到 80 年代),机器翻译都是通过研究源语言与目标语言的语言学信息来做的,也就是基于词典和语法生成翻译,这被称为基于规则的机器翻译(RBMT)。随着统计学的发展,研究者开始将统计模型应用于机器翻译,这种方法是基于对双语文本语料库的分析来生成翻译结果。这种方法被称为统计机器翻译(SMT),它的表现比 RBMT 更好,并且在 1980 年代到 2000 年代之间主宰了这一领域。1997 年,Ramon Neco 和 Mikel Forcada 提出了使用编码器-解码器结构做机器翻译的想法。几年之后的 2003 年,蒙特利尔大学 Yoshua Bengio 领导的一个研究团队开发了一个基于神经网络的语言模型,改善了传统 SMT 模型的数据稀疏性问题。他们的研究工作为未来神经网络在机器翻译上的应用奠定了基础。
2013 年,Nal Kalchbrenner 和 Phil Blunsom 提出了一种用于机器翻译的新型端到端编码器-解码器结构。该模型可以使用卷积神经网络(CNN)将给定的一段源文本编码成一个连续的向量,然后再使用循环神经网络(RNN)作为解码器将该状态向量转换成目标语言。他们的研究成果可以说是神经机器翻译(NMT)的诞生,神经机器翻译是一种使用深度学习神经网络获取自然语言之间的映射关系的方法。NMT 的非线性映射不同于线性的 SMT 模型,而且是使用了连接编码器和解码器的状态向量来描述语义的等价关系。此外,RNN 应该还能得到无限长句子背后的信息,从而解决所谓的长距离重新排序(long distance reordering)问题。但是,梯度爆炸或者消失问题让 RNN 实际上难以处理长距依存(long distance dependency),因此,NMT 模型一开始的表现并不好。
一年后的 2014 年,Sutskever et al. 和 Cho et al. 开发了一种名叫序列到序列(seq2seq)学习的方法,可以将 RNN 既用于编码器也用于解码器,并且还为 NMT 引入了长短时记忆(LSTM,是一种 RNN)。在门机制(gate mechanism)的帮助下,允许在 LSTM 中删除和更新明确的记忆,梯度爆炸/消失问题得到了控制,从而让模型可以远远更好地获取句子中的长距依存。
LSTM 的引入解决了长距离重新排序问题,同时将 NMT 的主要难题变成了固定长度向量(fixed-length vector)问题,不管源句子的长度几何,这个神经网络都需要将其压缩成一个固定长度的向量,这会在解码过程中带来更大的复杂性和不确定性,尤其是当源句子很长时。
自 2014 年 Yoshua Bengio 的团队为 NMT 引入了注意力(attention)机制之后,固定长度向量问题也开始得到解决。注意力机制最早是由 DeepMind 为图像分类提出的,这让神经网络在执行预测任务时可以更多关注输入中的相关部分,更少关注不相关的部分。当解码器生成一个用于构成目标句子的词时,源句子中仅有少部分是相关的。因此,可以应用一个基于内容的注意力机制来根据源句子动态地生成一个加权的语境向量(context vector),然后网络会根据这个语境向量而不是某个固定长度的向量来预测词。自那以后,NMT 的表现得到了显著提升,注意力编码器-解码器网络已经成为了 NMT 领域当前最佳的模型。
Transformer模型是在注意力机制上的进一步改进,不仅在Encoder-Decoder之间有注意力机制,其Encoder和Decoder自身也有自注意力机制(self-attention),即能注意输入序列的不同位置以计算该序列的表示的能力。
Transform模型原理
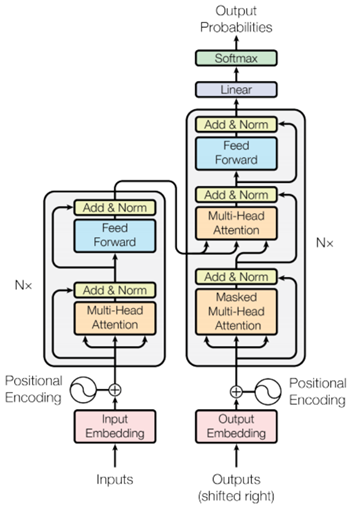
Transformer 模型的核心思想是自注意力机制(self-attention),能注意输入序列的不同位置以计算该序列的表示的能力。Transformer 是多层自注意力层组成的堆栈。
Transformer 模型与标准的具有注意力机制的序列到序列模型遵循相同的一般模式。输入语句经过 N 个编码器层,为序列中的每个词/标记生成一个输出,解码器关注编码器的输出以及它自身的输入(自注意力)来预测下一个词。
其模型架构图如下:
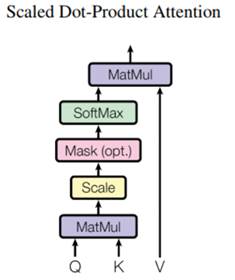
Transformer 使用的注意力函数有三个输入:Q(请求(query))、K(主键(key))、V(数值(value))。点积注意力被缩小了深度的平方根倍,这样做是因为对于较大的深度值,点积的大小会增大,从而推动 softmax 函数往仅有很小的梯度的方向靠拢,导致了一种很硬的softmax。
例如,假设 Q 和 K 的均值为0,方差为1。它们的矩阵乘积将有均值为0,方差为 dk。因此,dk 的平方根被用于缩放(而非其他数值),因为,Q 和 K 的矩阵乘积的均值本应该为 0,方差本应该为1,这样会获得一个更平缓的 softmax。
遮挡(mask)与 -1e9(接近于负无穷)相乘,这样做是因为遮挡与缩放的 Q 和 K 的矩阵乘积相加,并在 softmax 之前立即应用,目标是将这些单元归零,因为 softmax 的较大负数输入在输出中接近于零。当 softmax 在 K 上进行归一化后,它的值决定了分配到 Q 的重要程度。输出表示注意力权重和 V(数值)向量的乘积。这确保了要关注的词保持原样,而无关的词将被清除掉。
其公式和架构图如下:
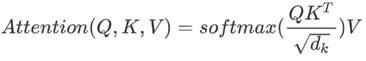
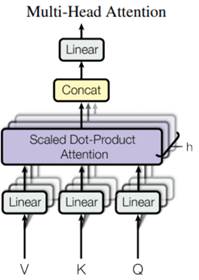
多头注意力由四部分组成:线性层并分拆成多头、按比缩放的点积注意力、多头及联、最后一层线性层。
每个多头注意力块有三个输入:Q(请求)、K(主键)、V(数值)。这些输入经过线性层,并分拆成多头。Q、K、和V被拆分到了多个头,而非单个的注意力头,因为多头允许模型共同注意来自不同表示空间的不同位置的信息。在分拆后,每个头部的维度减少,因此总的计算成本与有着全部维度的单个注意力头相同。将上面定义的缩放点积注意力函数应用于每个头(进行了广播以提高效率),然后将每个头的注意力输出连接起来,并放入最后的 Dense 层,最终输出注意力权重和输出。其公式和架构图如下:
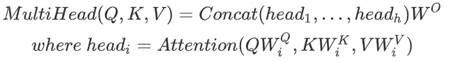
因为该模型并不包括任何的循环或卷积,所以模型添加了位置编码,为模型提供一些关于单词在句子中相对位置的信息。
位置编码向量被加到嵌入向量中,嵌入表示一个 d 维空间的标记,在 d 维空间中有着相似含义的标记会离彼此更近。但是,嵌入并没有对在一句话中的词的相对位置进行编码。因此,当加上位置编码后,词将基于它们含义的相似度以及它们在句子中的位置,在 d 维空间中离彼此更近。
这里采用正弦余弦的位置编码方式,其公式如下:
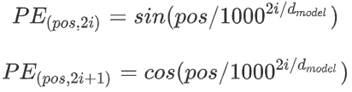
在进行预测时,采用强制教学(teacher force),即上一步的输出当做下一步的输入,逐步预测出整个序列。
Transform模型优缺点
一个 Transformer 模型用自注意力层而非 RNNs 或 CNNs 来处理变长的输入。这种通用架构有一系列的优势:
(1)它不对数据间的时间/空间关系做任何假设,这是处理一组对象的理想选择。
(2)层输出可以并行计算,而非像 RNN 这样的序列计算。
(3)远距离项可以影响彼此的输出,而无需经过许多 RNN 步骤或卷积层(4)它能学习长距离的依赖。在许多序列任务中,这是一项挑战。
该架构的目前的缺点是:
(1)对于时间序列,一个单位时间的输出是从整个历史记录计算的,而非仅从输入和当前的隐含状态计算得到,这可能效率较低。
(2)如果输入确实有时间/空间的关系,像文本,则必须加入一些位置编码,否则模型将有效地看到一堆单词。
