系统描述
系统介绍
系统基于ZooKeeper搭建Hadoop HA集群,在高可用分布式HDFS文件系统的基础上,搭建高可用分布式HBase数据库集群。
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是 Google Chubby一个开源的实现。它提供了简单原始的功能,分布式应用可以基于它实现更高级的服务,比如分布式同步,配置管理,集群管理,命名管理,队列管理。使用文件系统目录树作为数据模型。
Hadoop分布式集群采用主从架构,在Hadoop HA集群中,ZooKeeper用来解决SPOF单点故障问题。如果active namenod宕机,就从剩下的standby namenodes中选举出来一个新的active namenode,并且做到瞬时切换,使得在需求增长的前提下,分布式集群仍然可以向外提供服务。同样的,分布式HBase数据库也采用主从架构,在master server宕机的情况下,瞬时切换到backup master,使得HBase高可用。分布式HBase数据库的底层存储采用HDFS文件系统。
环境要求和版本选择
(1)四台Linux服务器,分别为Hadoop01、Hadoop02、Hadoop03、Hadoop04,采用Centos 6.8版本;
(2)Java采用JDK 1.8版本;
(3)ZooKeeper 采用 3.4.10版本;
(4)Hadoop 采用2.7.6版本;
(5)HBase采用 1.2.6版本;
集群规划和架构设计
Hadoop和HBase均采用主从架构模式,其系统内部均使用自己提供的负载均衡器。系统的集群规划如下表所示。
| Hadoop01 | Hadoop02 | Hadoop03 | Hadoop04 | |
|---|---|---|---|---|
| NameNode | √ | √ | ||
| DataNode | √ | √ | √ | √ |
| ResourceManager | √ | √ | ||
| NodeManager | √ | √ | √ | √ |
| JobHistoryServer | √ | |||
| ZooKeeper | √ | √ | √ | |
| JournalNode | √ | √ | √ | |
| Zkfc | √ | √ | ||
| HMaster | √ | √ | ||
| HRegionServer | √ | √ | √ | √ |
系统搭建
ZooKeeper集群安装
配置安排
安装ZooKeeper集群时需要注意集群的节点个数必须是奇数,因为奇数个数是为了方便进行选举leader。这里将Hadoop01、Hadoop02、Hadoop03和Hadoop04均作为ZooKeeper集群的节点,但是将Hadoop04节点中的角色固定设置为observer,observer其实跟follower类似,只不过是为了给ZooKeeper进行扩充之使用,不会改变原来集群的主从所属关系,仅仅只是接受请求,然后进行处理,没有投票的权利,也没有被选举成为leader的权利。
配置步骤
获取安装包
zookeeper-3.4.10.tar.gz解压
tar -zxvf zookeeper-3.4.10.tar.gz -C ~/apps/修改配置文件
vim zoo.cfg123456// znode数据存储系统中的所有节点的数据存储目录dataDir=/home/hadoop/data/zkdata/server.1=hadoop01:2888:3888server.2=hadoop02:2888:3888server.3=hadoop03:2888:3888server.4=hadoop04:2888:3888:observer在每个节点的/home/hadoop/data/zkdata/目录下创建一个myid的文件,该文件中直接存储一个id值即可
123hadoop01:echo 1 > myidhadoop02:echo 2 > myidhadoop03:echo 3 > myid配置环境变量
vim .bashrc12export ZOOKEEPER_HOME=/home/hadoop/apps/zookeeper-3.4.10export PATH=$PATH:$ZOOKEEPER_HOME/bin启动
在每个节点上都执行:
zkServer.sh start客户端连接与shell操作
客户端连接:
zkCli.sh -server hostname:2181
Hadoop HA集群安装
HA设计和配置安排
使用共享存储和ZooKeeper实现Hadoop HA。这里将Hadoop01作为NameNode的active节点,将Hadoop02作为NameNode的standby节点,Hadoop02是Hadoop01的热备,NameNode的元数据都存储在qjournal日志系统这个共享存储中,Hadoop01、Hadoop02、Hadoop03、Hadoop04都作为DataNode的节点,定时向NameNode发送报告和心跳。ZooKeeper中的zkfc进程监控NameNode的情况,当NameNode active节点失去心跳,即宕机时,自动切换,将standby节点激活,实现Hadoop集群的高可用。
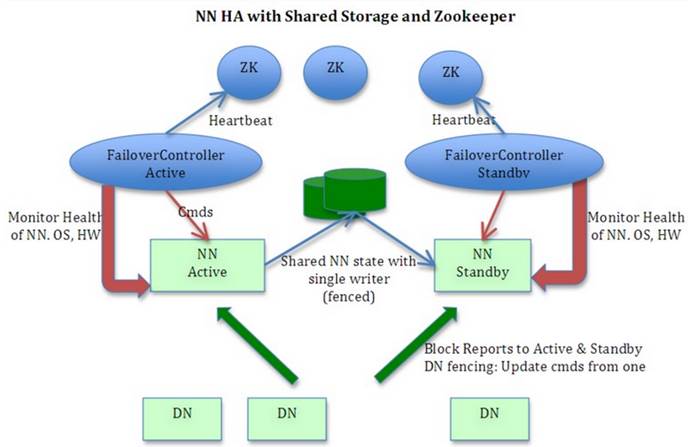
配置步骤
获取安装包
hadoop-2.7.6.tar.gz解压
tar -zxvf hadoop-2.7.6.tar.gz -C ~/apps/修改配置文件
hadoop-env.sh文件:
export JAVA_HOME=/home/hadoop/apps/jdk1.8.0_73core-site.xml文件:
12345678910111213141516171819202122232425<configuration> <!-- 指定hdfs的nameservice为myha01 --> <property> <name>fs.defaultFS</name> <value>hdfs://myha/</value> </property> <!-- 指定hadoop临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/data/hadoopdata/</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181</value> </property> <!-- hadoop链接zookeeper的超时时长设置 --> <property> <name>ha.zookeeper.session-timeout.ms</name> <value>1000</value> <description>ms</description> </property></configuration>hdfs-site.xml文件:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107<configuration> <!-- 指定副本数 --> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 配置namenode和datanode的工作目录-数据存储目录 --> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/data/hadoopdata/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/data/hadoopdata/dfs/data</value> </property> <!-- 启用webhdfs --> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.nameservices</name> <value>myha</value> </property> <!-- myha01下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.myha</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.myha.nn1</name> <value>hadoop01:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.myha.nn1</name> <value>hadoop01:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.myha.nn2</name> <value>hadoop02:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.myha.nn2</name> <value>hadoop02:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/myha</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/data/journaldata</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.myha</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 --> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <property> <name>ha.failover-controller.cli-check.rpc-timeout.ms</name> <value>60000</value> </property></configuration>
mapred-site.xml文件:
|
|
yarn-sitem.xml文件:
|
|
slaves文件:
|
|
分发,在一个节点上配置,分发到其他节点,配置信息全部一致
scp -r hadoop-2.7.6 hadoop02:~/apps/scp -r hadoop-2.7.6 hadoop03:~/apps/scp -r hadoop-2.7.6 hadoop04:~/apps/配置环境变量.bashrc
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.6export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin第一次启动
Hadoop HA集群启动前,需要先启动ZooKeeper集群。需要找到qjournal系统的所有节点执行:
hadoop-daemon.sh start journalnode,找到其中的一个HDFS主节点执行初始化:hadoop namenode -format。把当前初始化成功的那个namenode节点的工作目录中的数据文件全部拷贝到剩下的其他namenode节点中的对应目录:scp -r hadoopdata/ hadoop02:~/data/,选择其中的一个namenode节点然后执行命令去进行zkfc的初始化:hdfs zkfc –formatZK正式启动
启动hdfs:
start-dfs.sh启动yarn集群:
start-yarn.sh启动mr历史服务器:
mr-jobhistory-daemon.sh start historyserver
HBase HA集群安装
配置安排
HBase分布式数据库底层数据存储采用刚刚搭建的HDFS分布式文件系统,使用ZooKeeper来作为HMaster和Backup HMaster的协调,在HMaster失去心跳宕机时,Backup HMaster自动切换成active状态,实现高可用分布式数据库。这里将Hadoop01和Hadoop04作为HMaster节点,将Hadoop01、Hadoop02、Hadoop03、Hadoop04作为HRegionServer节点。
配置步骤
安装包
hbase-1.2.6.tar.gz解压
tar -zxvf hbase-1.2.6.tar.gz -C ~/apps/修改配置文件
hbase-env.sh文件:
export JAVA_HOME=/home/hadoop/jdk1.8.0_73export HBASE_MANAGES_ZK=falsehbase-site.xml文件:
1234567891011121314151617<property> <!-- 指定 hbase 在 HDFS 上存储的路径 --> <name>hbase.rootdir</name> <value>hdfs://myha/myhbase</value></property><property <!-- 指定 hbase 是分布式的 --> <name>hbase.cluster.distributed</name> <value>true</value></property><property> <!-- 指定 zk 的地址,多个用“,”分割 --> <name>hbase.zookeeper.quorum</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value></property>
regionservers文件:
|
|
backup-masters文件:
hadoop01
将hadoop的hdfs-site.xml、core-site.xml放在hbase的conf下
cp /home/hadoop/hadoop-2.7.6/etc/hadoop/core-site.xml .cp /home/hadoop/hadoop-2.7.6/etc/hadoop/hdfs-site.xml .将hbase的安装包发送到其他节点
scp -r hbase-1.2.6 hadoop01:$PWDscp -r hbase-1.2.6 hadoop02:$PWDscp -r hbase-1.2.6 hadoop03:$PWDscp -r hbase-1.2.6 hadoop04:$PWD启动
start-hbase.sh
系统测试与结果展示
系统测试
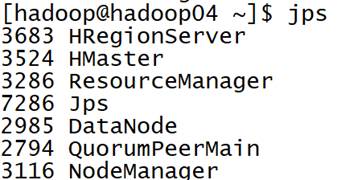
在四台机器上运行jps命令,查看相关进程是否启动。
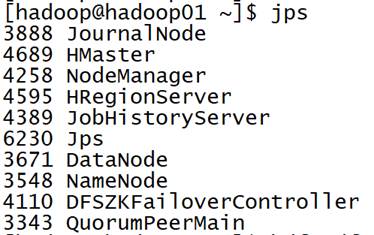
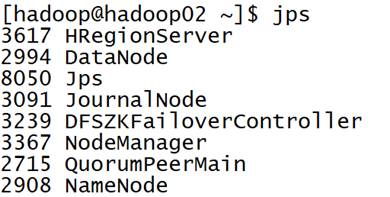
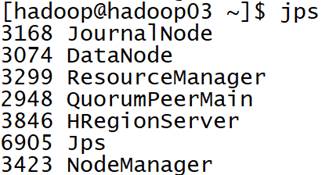
ZooKeeper状态查看
在四台机器上使用zkServer.sh status命令查看ZooKeeper的状态。




Hadoop HA展示
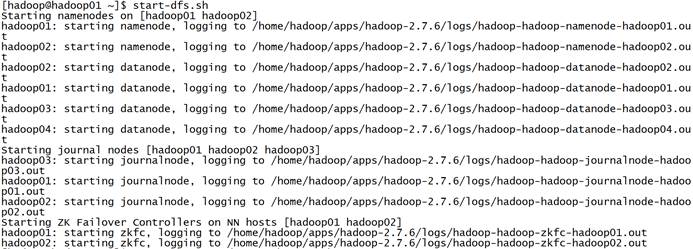
HDFS启动过程:
YARN启动过程:

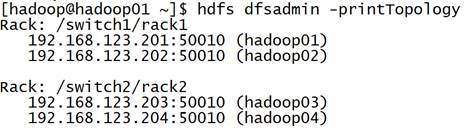
机架感知状态查看:
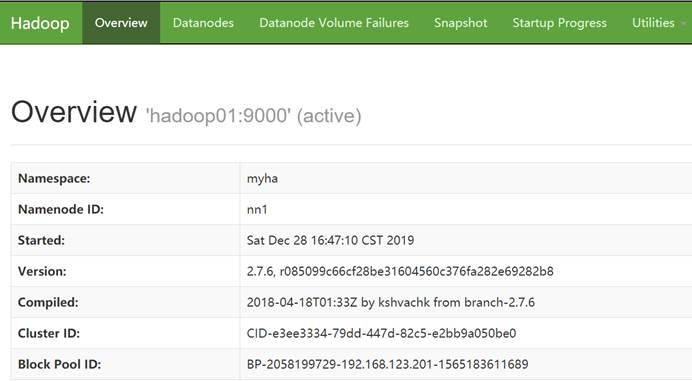
Web页面查看:
HBase HA展示
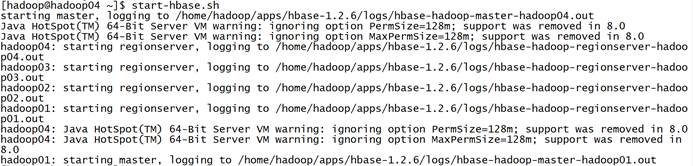
HBase启动过程:
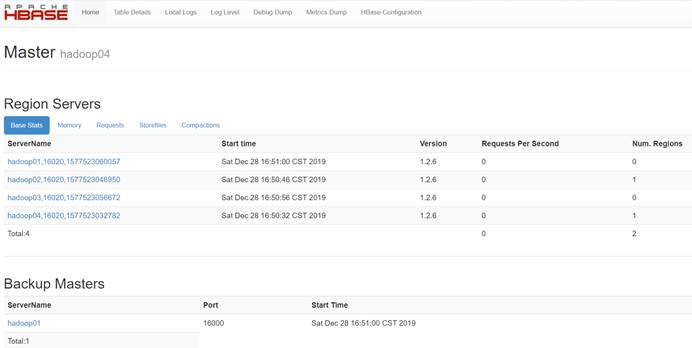
Web页面查看:
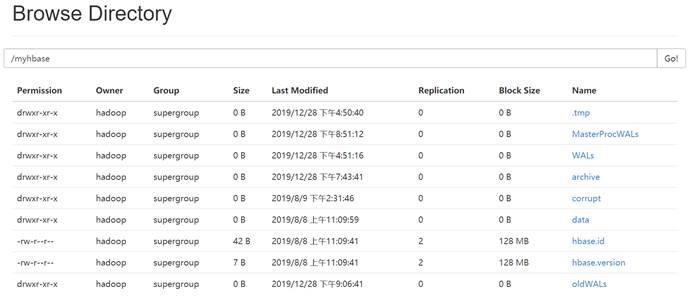
HBase底层存储情况:
总结
系统根据需求,进行架构设计,确定一主多从的架构,接着根据系统环境和版本兼容性的选择,确定最终系统中安装包的版本,然后在仅有的四台服务器上进行集群规划,尽量使得各个节点负载均衡。
通过搭建ZooKeeper分布式集群,以感知服务器上下线,接着基于ZooKeeper搭建Hadoop HA集群,保证HDFS文件系统高可用,再在高可用分布式HDFS文件系统的基础上搭建高可用分布式HBase数据库,完整实现这个过程,学习到分布式系统中关于数据一致性的知识,在系统中,均可保证最终一致性。掌握了ZooKeeper、Hadoop、HBase高可用集群的搭建部署,学习了在分布式文件系统HDFS之上,数据库的应用场景。
