本文记录Docker容器和K8S集群中一些监控命令。
Docker基本监控
自带常用命令
docker ps -a:查看进程docker top 容器id:查看容器资源利用docker status:实时查看容器资源
图形化工具weavescope
部署
|
|
本文记录Docker容器和K8S集群中一些监控命令。
自带常用命令
docker ps -a:查看进程docker top 容器id:查看容器资源利用docker status:实时查看容器资源图形化工具weavescope
部署
|
|
本文使用JavaScript实现基础数据结构:数组、链表、栈、队列、树
|
|
本文使用JavaScript实现基础排序算法和搜索算法
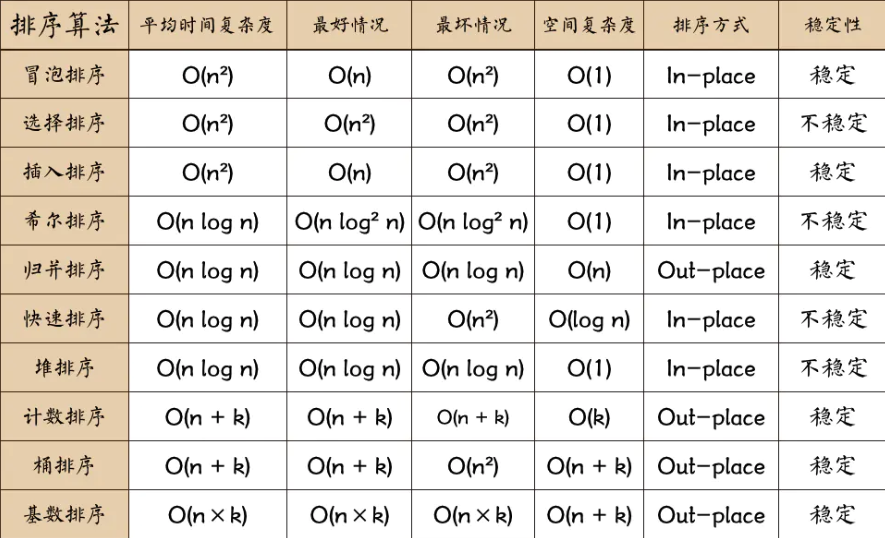
工作原理:冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。
算法描述:
本文使用JavaScript实现一些常用的算法思想
|
|
本文使用Docker中Ubuntu16.04镜像,搭建MiniConda环境,在conda之上搭建Ray集群环境
编写Dockerfile文件,构建镜像,换源为阿里云:
|
|
将Dockerfile文件放在用户目录下,运行下面命令构建镜像:
|
|
本文在Centos7.8上安装Docker,并且加载国内镜像
下载镜像:https://mirrors.tuna.tsinghua.edu.cn/centos/7.8.2003/isos/x86_64/
虚拟机VMware安装Centos7:步骤略
固定ip地址:图形化设置
设置DNS:
|
|
Centos镜像设置:
建议先备份 CentOS-Base.repo
|
|
然后编辑 /etc/yum.repos.d/CentOS-Base.repo 文件,在 mirrorlist= 开头行前面加 # 注释掉;并将 baseurl= 开头行取消注释(如果被注释的话),把该行内的域名(例如mirror.centos.org)替换为 mirrors.tuna.tsinghua.edu.cn。
最后,更新软件包缓存
|
|
本文使用MiniConda搭建Ray集群环境
通过修改用户目录下的 .condarc 文件。Windows 用户无法直接创建名为 .condarc 的文件,可先执行 conda config --set show_channel_urls yes 生成该文件之后再修改
|
|
即可添加 Anaconda Python 免费仓库。
运行 conda clean -i 清除索引缓存,保证用的是镜像站提供的索引。
|
|
系统基于ZooKeeper搭建Hadoop HA集群,在高可用分布式HDFS文件系统的基础上,搭建高可用分布式HBase数据库集群。
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是 Google Chubby一个开源的实现。它提供了简单原始的功能,分布式应用可以基于它实现更高级的服务,比如分布式同步,配置管理,集群管理,命名管理,队列管理。使用文件系统目录树作为数据模型。
Hadoop分布式集群采用主从架构,在Hadoop HA集群中,ZooKeeper用来解决SPOF单点故障问题。如果active namenod宕机,就从剩下的standby namenodes中选举出来一个新的active namenode,并且做到瞬时切换,使得在需求增长的前提下,分布式集群仍然可以向外提供服务。同样的,分布式HBase数据库也采用主从架构,在master server宕机的情况下,瞬时切换到backup master,使得HBase高可用。分布式HBase数据库的底层存储采用HDFS文件系统。
机器翻译(MT)是借机器之力,自动地将一种自然语言文本(源语言)翻译成另一种自然语言文本(目标语言)。使用机器做翻译的思想最早由 Warren Weaver 于 1949 年提出,在很长一段时间里(20 世纪 50 年代到 80 年代),机器翻译都是通过研究源语言与目标语言的语言学信息来做的,也就是基于词典和语法生成翻译,这被称为基于规则的机器翻译(RBMT)。随着统计学的发展,研究者开始将统计模型应用于机器翻译,这种方法是基于对双语文本语料库的分析来生成翻译结果。这种方法被称为统计机器翻译(SMT),它的表现比 RBMT 更好,并且在 1980 年代到 2000 年代之间主宰了这一领域。1997 年,Ramon Neco 和 Mikel Forcada 提出了使用编码器-解码器结构做机器翻译的想法。几年之后的 2003 年,蒙特利尔大学 Yoshua Bengio 领导的一个研究团队开发了一个基于神经网络的语言模型,改善了传统 SMT 模型的数据稀疏性问题。他们的研究工作为未来神经网络在机器翻译上的应用奠定了基础。
本文主要收集大数据Hadoop相关知识点总结。
主节点NameNode:掌管文件系统目录树,处理客户端读写请求,负责管理整个文件系统的元数据,负责维持文件的副本数量
SecondaryNameNode:主要是给NameNode分担压力,把NN的fsimage和edit log做定期融合,融合后传给NN,以确保备份到的元数据是最新的,是冷备。
从节点DataNode:存储整个集群所有数据块,处理真正的数据读写,通过心跳信息定期地向NameNode汇报自身保存的文件块信息